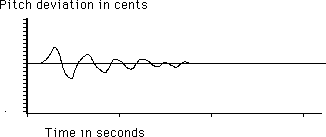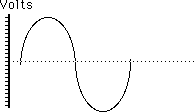|
|
Home | Audio | DIY | Guitar | iPods | Music | Brain/Problem Solving | Links| Site Map
This work is licensed under a Creative Commons License.
The Mathematics of Electronic Music
One of the difficult aspects of the study of electronic music is the accurate description of the sounds used. With traditional music, there is a general understanding of what the instruments sound like, so a simple notation of 'violin', or 'steel guitar' will convey enough of an aural image for study or performance. In electronic music, the sounds are usually unfamiliar, and a composition may involve some very delicate variations in those sounds. In order to discuss and study such sounds with the required accuracy, we must use the tools of mathematics. There will be no proofs or rigorous developments, but many concepts will be illustrated with graphs and a few simple functions. Here is a review of the concepts you will encounter:
Hertz
In dealing with sound, we are constantly concered with frequency, the number of times some event occurs within a second. In old literature, you will find this parameter measured in c.p.s., standing for cycles per second. In modern usage, the unit of frequency is the Hertz, (abbr. hz) which is officially defined as the reciprocal of one second. This makes sense if you remember that the period of a cyclical process, which is a time measured in seconds, is equal to one over the frequency. (P=1/f) Since we often discuss frequencies in the thousands of Hertz, the unit kiloHertz (1000hz=1khz) is very useful.
Exponential functions
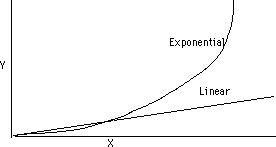
Many concepts in electronic music involve logarithmic or exponential relationships. A relationship between two parameters is linear if a constant ratio exists between the two, in other words, if one is increased, the other is increased a proportianal amount, or in math expression:
Y=kX
where k is a number that does not change (a constant).
A relationship between two parameters is exponential if the expression has this form:
Y=k^x
In this situation, a small change in X will cause a small change in Y, but a moderate change in X will cause a large change in Y. The two kinds of relationship can be shown graphically like this:
One fact to keep in mind whenever you are confronted with exponential functions: X^0=1 no matter what X is.
Logarithms
A logarithm is a method of representing large numbers originally developed for use with mechanical calculators. It is the inverse of an exponential relationship. If Y=10^X, X is the logarithm (base 10)[1] of Y. This system has several advantages; it keeps numbers compact (the log of1,000,000 is 6), and there are a variety of mathematical tricks that can be performed with logarithms. For instance, the sum of the logarithms of two numbers is the logarithm of the product of the two numbers-if you know your logs (or have a list of them handy), you can multiply large numbers with a mechanical adder. (This is what a slide rule does.) Two times the logarithm of a number is the log of the square of that number, and so forth.
We find logarithmic and exponential relationships many places in music. For instance the octave relationship may be expressed as Freq= F*2^n where F is the frequency of the original pitch and n is the number of octaves you want to raise the pitch. We discuss the logarithmic nature of loudness at length in Hearing and the Ear and Decibels.
Decibels
The strength of sounds, and related electronic measurements are often expressed in decibels (abbr. dB). The dB is not an absolute measurement; it is based upon the relative strengths of two sounds. Furthermore, it is a logarithmic concept, so that very large ratios can be expressed with small numbers. The formula for computing the decibel relationship between two sounds of powers A and B is 10 log(A/B).
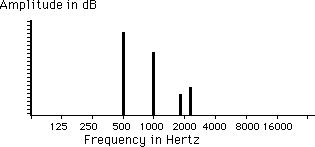
The spectral plot
A spectral plot is a map of the energy of a sound. It shows the frequency and strength of each component.
Each component of a complex sound is represented by a bar on the graph. The frequency of a component is indicated by its position to the right or left, and its amplitude is represented by the height of the bar. The frequencies are marked out in a manner that gives equal space to each octave of the audible spectrum. The amplitude scale is not usually marked, since we are usually only concerned with the relative strengths of each component. It is important to realize that whenever a spectral plot is presented, we are talking about the contents of sound. In the example, the sound has four noticable components, at 500 hz, 1000, just below 2000 hz, and just above 2000 hz.
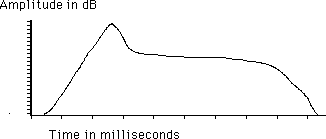
Envelopes
Envelopes are a very familiar type of graph, showing how some parameter changes with time.
This example shows how a sound starts from nothing, builds quickly to a peak, falls to an intermediate value and stays near that value a while, then falls back to zero. When we use these graphs, we are usually more concerned with the rate of the changes that take place than with any actual values.
A variation of this type of graph has the origin in the middle:
Even when the numbers are left off, we understand that values above the line are positive and values below the line are negative. The origin does not represent 'zero frequency', it represents no change from the expected frequency.
Spectral Envelopes
The most complex graph you will see combines spectral plots and envelopes in a sort of three dimensional display:
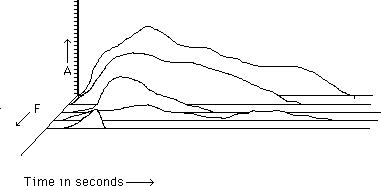
This graph shows how the amplitudes of all of the components of a sound change with time. The 'F' stands for frequency, which is displayed in this instance with the lower frequency components in the back. That perspective was chosen because the lowest partials of this sound have relaltively high amplitudes. A different sound may be best displayed with the low components in front.
Frequency Response
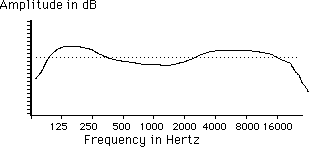
When we are discussing the effects of various devices on sounds, we often are concerned with the way such effects vary with frequency. The most common frequency dependent effect is a simple change of amplitude; in fact all electronic devices show some variation of output level with frequency. We call this overall change frequency response, and usually show it on a simple graph:
The dotted line represents 0 dB, which is defined as the 'flat' output, which would occur if the device responded the same way to all frequencies of input. This is not a spectral plot; rather, it shows how the spectrum of a sound would be changed by the device. In the example, if a sound with components of 1 kHz, 3kHz, and 8kHz were applied, at the device output the 1kHz partial would be reduced by 2dB, the 8kHz partial would be increased by 3dB, and the 3kHz partial would be unaffected. There would be nothing happening at 200Hz since there was no such component in the input signal.
When we analyze frequency response curves, we will often be interested in the rate of change, or slope of the curve. This is expressed in number of dB change per octave. In the example, the output above 16kHz seems to be dropping at about 6 dB/oct.
Waveforms
Once in a while, we will look at the details of the change in pressure (or the electrical equivalent, voltage) over a single cycle of the sound. A graph of the changing voltage is the waveform, as:
Time is along the horizontal axis, but we usually do not indicate any units, as the waveform of a sound is more or less independent of its frequency. The graph is always one complete period. The dotted line is the average value of the signal. This value may be zero volts, or it may not. The amplitude of the signal is the maximum departure from this average.
Sine waves
The most common waveform we will see is the sine wave, a graph of the function v=AsinT. Understanding of some of the applications of sine functions in electronic music may come more easily if we review how sine values are derived.
You can mechanically construct sine values by moving a point around a circle as illustrated. Start at the left side of the circle and draw a radius. Move the point up the circle some distance, and draw another radius. The height of the point above the original radius is the sine of the angle formed by both radii. The sine is expressed as a fraction of the radius, and so must fall between 1 and -1.
Imagine that the circle is spinning at a constant rate. A graph of the height of the point vs. time would be a sine wave. Now imagine that there is a new circle drawn about the point that is also spinning. A point on this new circle would describe a very complex path, which would have an equally complex graph. It is this notion of circles upon circles upon circles which is the basis for the concept of breaking waveforms into collections of sine waves. (See the essay Sound Spectra for more information.)
This fanciful machine shows how complex curves are made up of simple ones.
The Harmonic Series
A mathematical series is a list of numbers in which each new member is derived by performing some computation with previous members of the list. A famous one is the Fibonacci series, where each new number is the sum of the two previous numbers (1,1,2,3,5,8 etc.) In music, we often encounter the harmonic series, constructed by multiplying a base number by each integer in turn. The harmonic series built on 5 would be 5,10,15,20,25,30 and so forth. The number used as the base is called the fundamental, and is the first number in the series. Other members are named after their order in the series, so you would say that 15 is the third harmonic of 5. The series was called harmonic because early mathematicians considered it the foundation of musical harmony. (They were right, but it is only part of the story.)
Temperament
One of the aspects of music that is based on tradition is which frequencies of sound may be used for 'correct' notes. The concept of the octave, where one note is twice the frequency of another is almost universal, but the number of other notes that may be found between is highly variable from one culture to another, as is the tuning of those notes. In the western European tradition, there are twelve scale degrees, which are generally used in one or two assortments of seven. For the past hundred and fifty years or so, the tunings of these notes have been standardized as dividing the octave into twelve equal steps. The western equal tempered scale can then be defined as a series built by multiplying the last member by the twelfth root of two (1.05946). The distance between two notes is known by the musical term interval. (Frequency specifications are not very useful when we are talking about notes.) The smallest interval is the half step, which can be further broken down into one hundred units called cents.
Equal temperament has a variety of advantages over the alternatives, the most notable one being the ability of simple keyboard instruments to play in any key. The major disadvantage of the system is that none of the intervals beside the octave is in tune. To justify that last statement we have to define "in tune". When two musicians who have control of their instruments attempt to play the same pitch, they will adjust their pitch so the resulting sound is beat free. (Beating occurs when two tones of almost the same frequency are combined. The beat rate is the difference between the frequencies.) If the two attempt to play an interval expected to be consonant, they will also try for a beat free effect. This will occur when the frequencies of the notes fall at some simple whole number ratio, such as 3:2 or 5:4. If the instruments are restricted to equal tempered steps, that 5:4 ratio is unobtainable. The actual interval (supposed to be a third) is almost an eighth of a step too large.
It is possible to build scales in which all common intervals are simple ratios of frequency. It was such scales that were replaced by equaltemperament. We say scales-plural, because a different scale is required for each key; if you build a pure scale on C and one on D, you find that some notes which are supposed to occur in both scales come out with different frequencies. String instruments, and to some extent winds can deal with this, but keyboard instruments cannot. If you combine a musical style that requires modulation from key to key with the popularity keyboards have had for the last two centuries you have a situation where equal temperament is going to be the rule.
I wouldn't even bring this topic up if it weren't for two factors. One is that the different temperaments have a strong effect on the timbres achieved when harmony is part of a composition. The other is that the techniques of electronic music offer the best of both systems. It is possible to have the nice intonation of pure scales and the flexability for modulation offered by equal temperament. Composers are starting to explore the possibilities, and some commercial instrument makers are including multi-temperament capability on their products, so the near future may hold some interesting developments in the area.
Peter Elsea 1996
Home | Audio | DIY | Guitar | iPods | Music | Links | Site Map | Contact
![]()